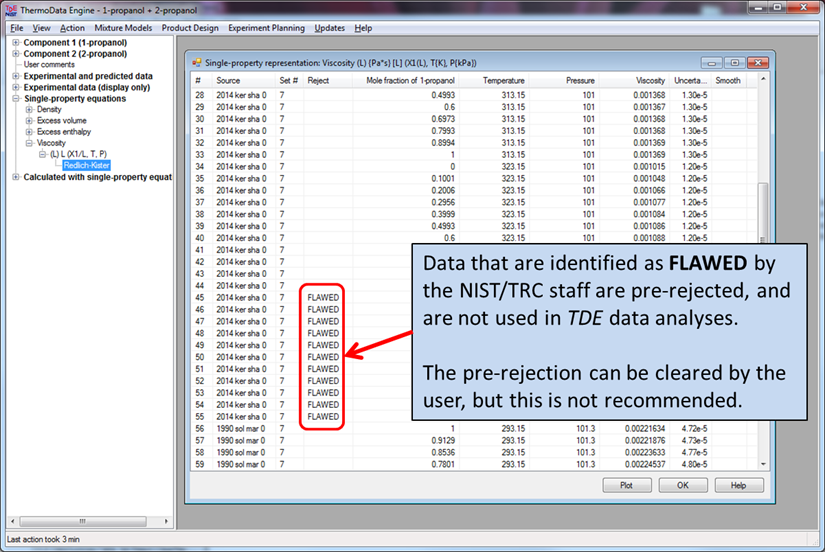
Flawed Data
The staff of the NIST Thermodynamics Research Center identify and repair numerous problems in data sets published in the peer-reviewed literature. At times, the experimental data cannot be repaired or are clearly erroneous for unknown reasons. In order to avoid any skewing of fitting procedures in TDE due to grossly erroneous data, "flawed" data are pre-rejected and are not used in any fitting procedures. The expert user can override the pre-rejection, but this is not recommended.Typically, "flawed" data are identified through comparisons between multiple data sources for the same or closely related properties. An example would be data for a mixture for which the endpoints show very large deviations from numerous literature sources. If the endpoints are grossly in error, the mixture data cannot be correct. In such cases, the compound may be mis-identified in the article, but unfortunately, such errors can rarely be repaired.
"FLAWED DATA" are identified in the Reject column of data tables in TDE.